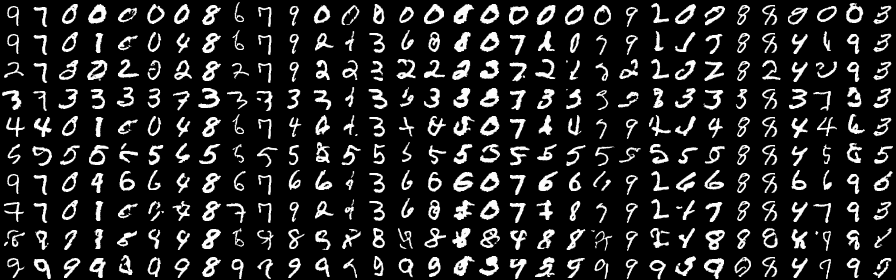
Digits guided with a classifier that wasn’t trained with
appropriate noise. Each row should be from a different
digit.
As discussed in lecture 23, we can guide the steps of a denoising diffusion model by using the gradients from a classifier. This is conceptually similar to the gradients you saw in the previous homework, where some pixels of the input image are correlated with a particular class. The correlations of individual pixels with a target class can be used to slightly nudge the values of those pixels during the denoising process, making it more likely that the image will end up being from the desired class. We are going to use the digits dataset for this homework.
The steps to doing this are:
Supporting files are in the homework description on canvas.
If you don’t add noise to the classifier, it will only have strong gradients when the digit is nearly decoded, and your results won’t be very guided.
Digits guided with a classifier that wasn’t trained with
appropriate noise. Each row should be from a different
digit.
If you add noise to the images during classifier training, you will have a much higher chance of success.

Digits guided with a classifier that was trained with
appropriate noise in the images.
The noise should follow the same sampling as what was used in the denoising diffusiong model during training. The following class can be used for that purpose. Use 1000 as the number of steps.
This is an example, the class, with decoding functions, will be provided in noisifier.py
# Betas are described as a hyperparametr in the UDL. See equation 18.1
# We want to match the noise generated in the reference diffuser,
# found in https://github.com/bot66/MNISTDiffusion
class Noisifier:
def __init__(self, num_steps):
super().__init__()
epsilon = 0.008
self.num_steps = num_steps
steps = torch.linspace(0, num_steps, steps=num_steps+1, dtype=torch.float32)
f_t=torch.cos(((steps/num_steps+epsilon)/(1.0+epsilon))*math.pi*0.5)**2
betas=torch.clip(1.0-f_t[1:]/f_t[:num_steps], 0.0, 0.999)
# The alpha_t values are the cumulative products of 1-beta_i, from i=1 to t
# See UDL equations 18.7
alphas = 1.0 - betas
alphas_cumprod = torch.cumprod(alphas, dim=-1)
self.sqrt_alphas_cumprod = torch.sqrt(alphas_cumprod)
self.sqrt_one_minus_alphas_cumprod = torch.sqrt(1.0 - alphas_cumprod)
def z_at_t(self, x_0, t):
noise=torch.randn_like(x_0)
with torch.no_grad():
# See equation 18.7 in UDL
return self.sqrt_alphas_cumprod.gather(-1,t).reshape(x_0.shape[0],1,1,1)*x_0+ \
self.sqrt_one_minus_alphas_cumprod.gather(-1,t).reshape(x_0.shape[0],1,1,1)*noise
def z_at_random(self, x_0):
noise=torch.randn_like(x_0)
# Select random indices
ts = torch.tensor(random.choices(range(self.num_steps), k=x_0.size(0)), dtype=torch.long)
with torch.no_grad():
# See equation 18.7 in UDL
return self.sqrt_alphas_cumprod.gather(-1, ts).reshape(x_0.size(0), 1, 1, 1)*x_0 + \
self.sqrt_one_minus_alphas_cumprod.gather(-1, ts).reshape(x_0.size(0), 1, 1, 1)*noiseJust to be sure we all load the MNIST digits data the same way, use torchvision and this function:
def create_mnist_dataloaders(batch_size,image_size=28,num_workers=4):
# Ensure images are the correct size and convert them to tensors
# Map into a range from -1 to 1: ([0,1] - 0.5)/0.5 -> [-1,1]
preprocess=transforms.Compose([transforms.Resize(image_size),\
transforms.ToTensor(),\
transforms.Normalize([0.5],[0.5])])
# Download the dataset into a local mnist_data directory
train_dataset=MNIST(root="./mnist_data",
train=True,
download=True,
transform=preprocess
)
test_dataset=MNIST(root="./mnist_data",
train=False,
download=True,
transform=preprocess
)
return (DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=num_workers),
DataLoader(test_dataset,batch_size=batch_size,shuffle=True,num_workers=num_workers))Your training code should look something like this:
# Set a training device. You can launch a GPU job via slurm on the ilab machines, or just use the CPU.
if args.device is None:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
else:
device = torch.device(args.device)
train_dataloader, test_dataloader = create_mnist_dataloaders(batch_size=args.batch_size,image_size=28)
# Make a model, optimizer, and loss function
# TODO
noisifier = Noisifier(num_steps = 1000)
for epoch in range(epochs):
total_loss = 0.0
matches = 0
model.train()
total = 0
for j, (X,Y) in enumerate(train_dataloader):
# Add noise during training, matching the noise used in the denoising diffuser.
X = noisifier.z_at_random(X).to(device)
# Zero gradients before gradient calculation
optimizer.zero_grad()
y_hat=model(X)
loss=criterion(y_hat, Y.to(device))
with torch.no_grad():
classes = torch.argmax(y_hat, dim=1).cpu()
matches += torch.sum(classes == Y)
total += Y.size(0)
total_loss += loss.item()
# Gradient calculation
loss.backward()
# Update weights
optimizer.step()
epoch_loss = total_loss / total
print(f"Epoch {epoch} training loss {epoch_loss}")
print(f"Epoch {epoch} accuracy {matches/total}")
# Send the model back to the CPU before saving it
model.eval().cpu()
torch.save(model.state_dict(),"noisy_classifier_parameters.pt")if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--random_seed",
required=False,
type=int,
default=112,
help="The random seed.")
parser.add_argument(
"--device",
required=False,
type=str,
default=None,
help="Override the automatically determined device (cuda or cpu).")
parser.add_argument(
"--stochastic_depth",
required=False,
action='store_true',
default=False,
help="Enable stochastic depth.")
parser.add_argument(
"--timesteps",
required=False,
type=int,
default=1000,
help="The timesteps.")
parser.add_argument(
"--target_class",
required=False,
type=int,
default=0,
help="The target class.")
args = parser.parse_args()
# Seed all of the random number generators for repeatability.
# Keep in mind though, that some algorithms are nondeterministic, so this
# doesn't guarantee fully repeatable results.
torch.manual_seed(args.random_seed)
random.seed(args.random_seed)
if args.device is None:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
else:
device = torch.device(args.device)
print(f"Using device: {device}")
denoiser = torch.load("denoiser_unet.pkl", weights_only=False)
denoiser.eval()
denoiser.to(device)
# TODO Load your trained classifier into a variable named "classifier"
classifier.to(device)
classifier.eval()
noisifier = Noisifier(num_steps = args.timesteps).to(device)
# Make a batch
z=torch.randn((32, 1, 28, 28), device=device)
indices = list(range(args.timesteps))[::-1]
for t in indices:
# The time
t_batch = torch.full((z.size(0),), t, device=device, dtype=torch.long)
# Estimate the noise with the diffusion model
with torch.no_grad():
# Forward through the unet
noise_estimate = denoiser(z, t_batch)
# Get the mean and variance estimates for the image pixels
mean, var = noisifier.sample(z.to(device), t_batch.to(device), noise_estimate.to(device))
print(f"Step {t}")
if t > 0:
# Find the classifier gradient
# This will be similar to what you did in homework 4
# Begin by making a copy of z that requires gradients
# zero the classifier's gradients
# classify z
# Go backwards through the target class
# You can also go backwards through the negative of other classes
# For example: guidance_loss = class_probs - nonclass_probs
# Depending upon your classifier, that could provide stronger guidance.
# Get the gradients and add them to the pixel means
# guided_mean = mean + scale * torch.sqrt(var) * guidance
# You will have to determine a scale that is appropriate.
# Too small, and you won't change the image classes.
# Too large, and you'll remove any variability.
# Get the next z by adding noise back to z
noise = torch.randn_like(z)
z = guided_mean + torch.sqrt(var) * noise
else:
# The final prediction doesn't need variance or guidance
# But we do need to convert from the -1 to 1 range back to 0 to 1
x = (mean + 1.0)/2.0
with torch.no_grad():
class_outputs = classifier(mean)
classes = torch.argmax(class_outputs, dim=1)
print(f"Final class predictions: {classes}")
# Find the "best" representative
best_idx = torch.argmax(class_outputs[:,args.target_class])
print(class_outputs[:,args.target_class])
print(f"Best index is {best_idx} is p = {class_outputs[:,args.target_class][best_idx]}")
for i in range(32):
x[i].clamp_(0., 1.)
x[i] = 255 * x[i]
Image.fromarray(x[i].reshape((28, 28)).cpu().numpy().astype(numpy.uint8)).save(f"denoised_target_{args.target_class}_digit_{i}.png")
if i == best_idx:
Image.fromarray(x[i].reshape((28, 28)).cpu().numpy().astype(numpy.uint8)).save(f"best_denoised_target_{args.target_class}.png")Your program should be able to output images that will mostly match the requested class. See the images above for examples.
Name your program “hw05.py” and submit it through canvas, along with the pretrained classifier you use to guide your diffusion.Your code will be tested in a directory with noisifier.py, unet.py, denoiser_unet.pkl, and whatever other files you submit.