The final question in lecture 8 was confusing, and it’s because I didn’t reread the options carefully. The statement in question was this one:
c. If two cluster means are equidistant, the cluster with the lower variance has higher responsibility for the point.
The statement is ambiguous as phrased, so saying it is false would be reasonable. The statement should have read something like this:
c. If a point is near to two cluster means, the cluster with the lower variance has higher responsibility for the point.
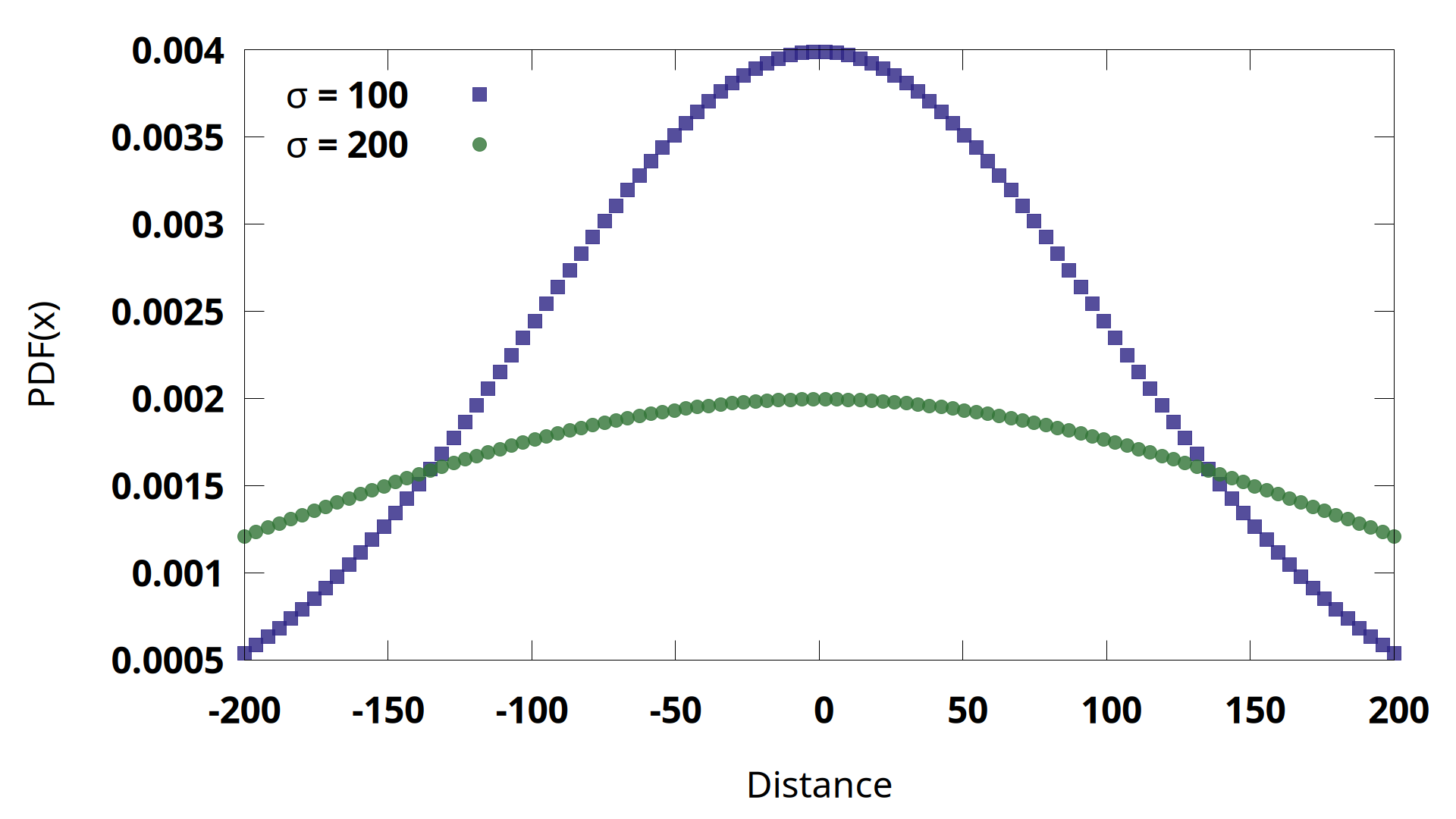
That’s too squishy for a statement on a test, but is at least correct. Let me explain though, using some graphs. First, here are two overlapping gaussians with the same mean, 0, and two different standard deviations:
The higher variance gaussian is flatter, so near the mean the lower variance gaussian has a sharper peak. The PDF translates directly into the negative log likelihood (NLL) that we assign to the possibility of each point coming from any particular cluster. In this case, imagine that the two clusters have exactly the same mean, 0, for this column of data. The NLL would vary according to the point’s distance like this:
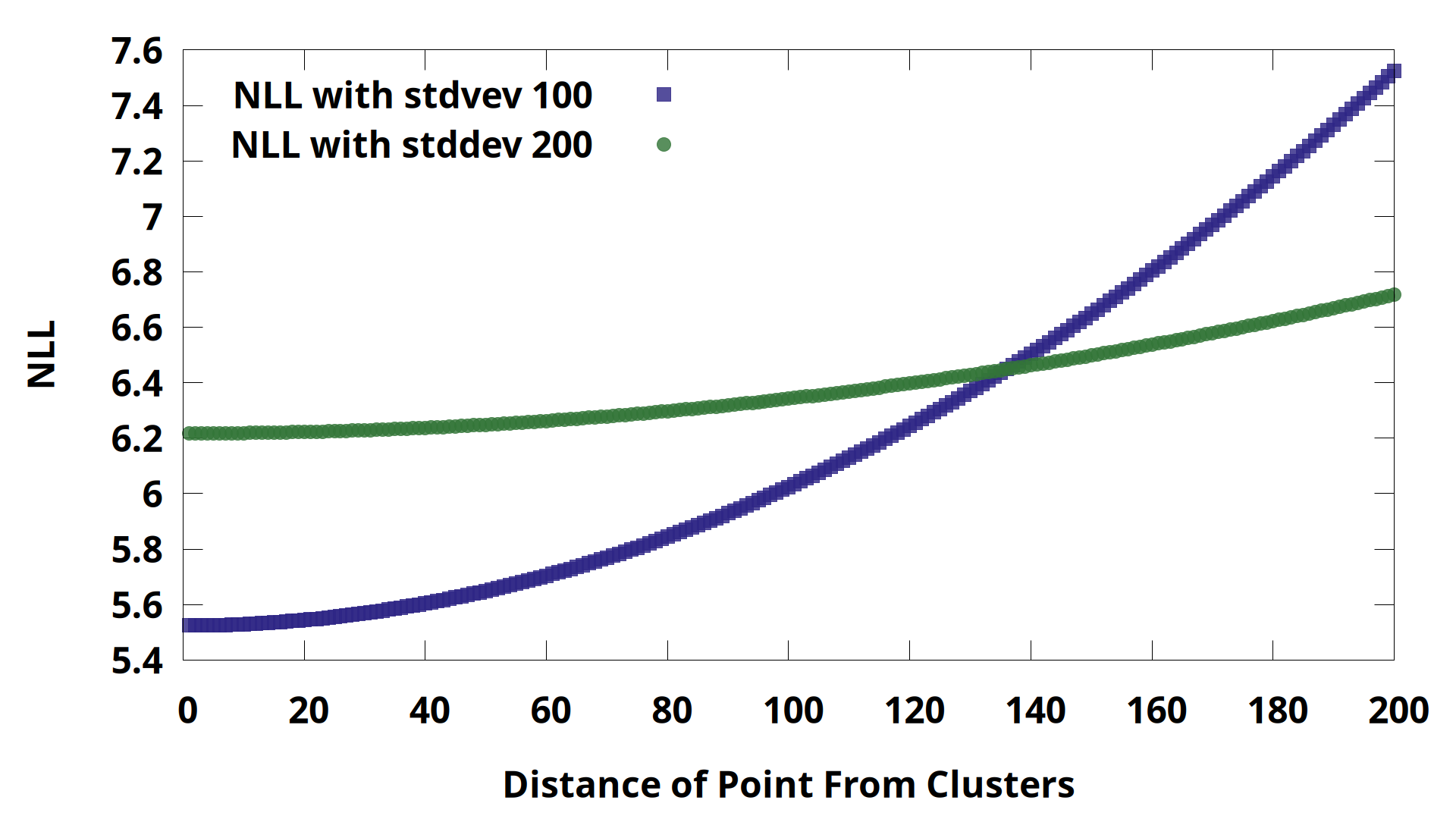
The point is more likely to have come from the low variance gaussian while it is “close” to the cluster means. We could also plot the ratio of the PDF values directly.
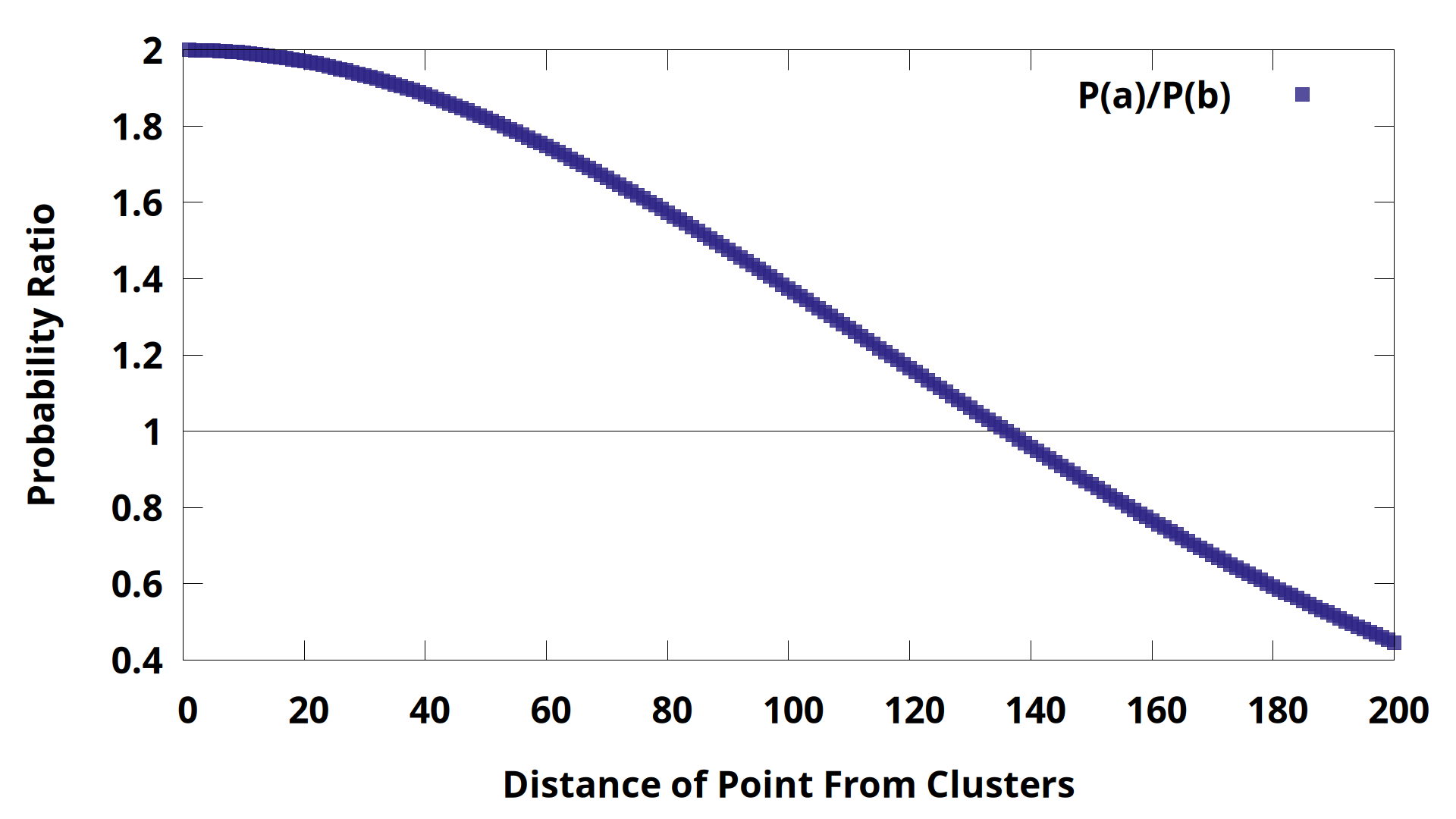
A value of 1 corresponds to equal likelihood. When The probably of coming from gaussian A is higher, the radio is >1. At <1, the probability of coming from gaussian B is higher. This is closely related to the soft responsibility, but instead of P(A)/P(B) we compare P(A) to the sum of all probabilities.
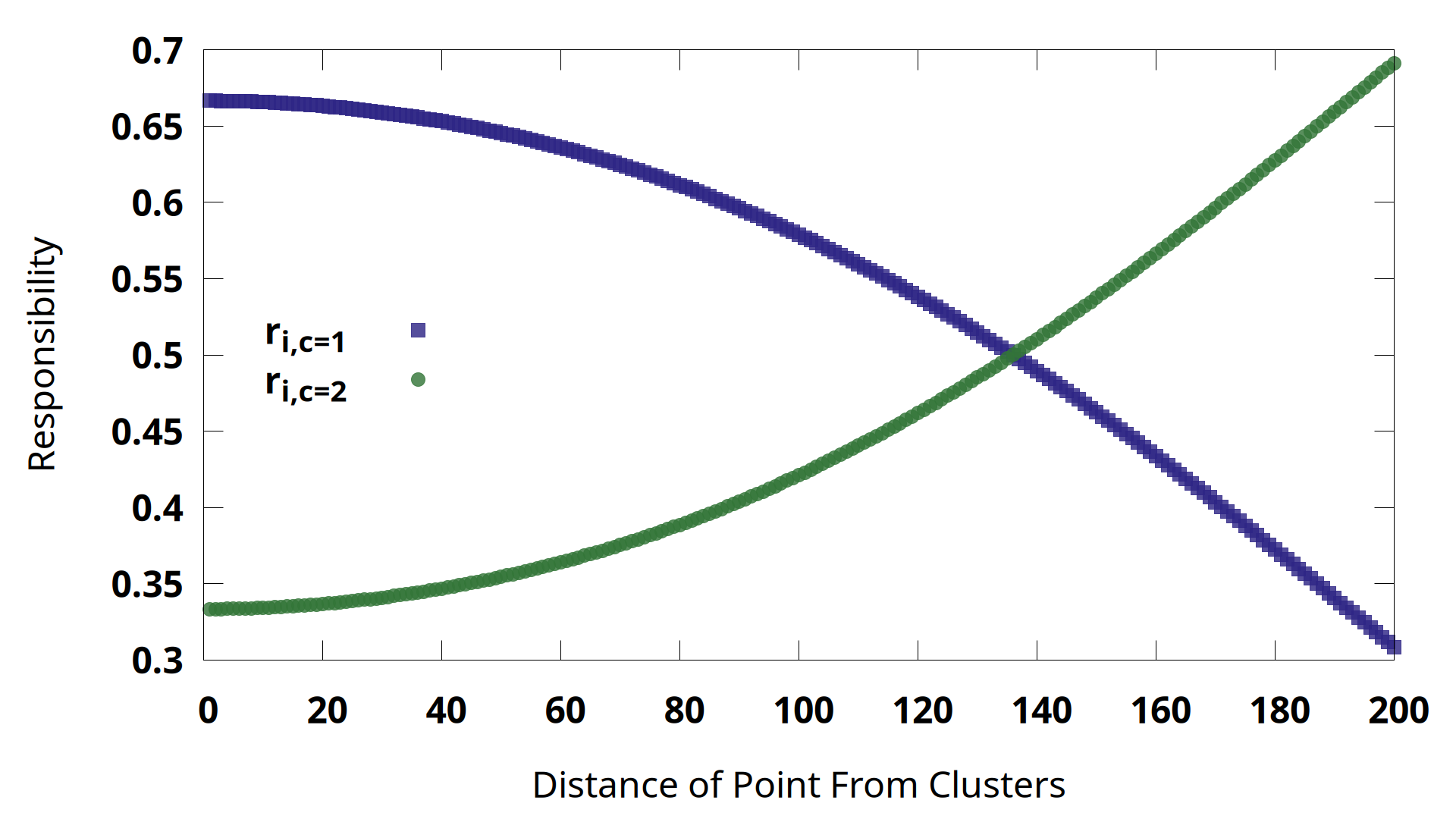
To properly follow the mixture of experts, the responsibility should also take into account the expert gating priors. For each expert, these are just the number of points assigned to that expert divided by the total number of points. This will gradually “squeeze out” any experts that are assigned to only a couple of points that could also be explained by one of the other experts. This helps keep the mixture of experts from overfitting its model to features that aren’t statistically meaningful. In our example though, let’s assume that both of our gaussian experts have a roughly equal number of points assigned to them, so the prior terms cancel and we simply compare the probabilities from the guassian distributions.
Soft clustering makes the mixture of experts very powerful. It properly models overlapping distributions, even allowing multiple distributions with identical means but different variances. If the two expert gaussians from this example were used in a mixture model, they could cluster data where one cluster is inside of the other. They would still make mistakes since points near the center could have come from either distribution, but with an additional column of data this may be enough to separate two overlapping clusters.